Basic Concepts
Overview
Before we delve into our design of XLang Agents, let's briefly introduce some foundational concepts upon which XLang Agents are built. There has been a surge of discussion around Large Language Model (LLM)-powered agents recently, ranging from their definition in the traditional Reinforcement Learning field to their role as helpful assistants.
Our XLang Agents are tailored for real-world scenarios, specifically:
- They aim to address human challenges in tangible concrete contexts, such as data analysis or real estate services; NOT general chitchat agents.
- They allow users to provide feedback in natural language to guide the agent towards better task completion and exploration; NOT limited to processing single-turn human intent.
- They are equipped with robust tools like code, plugins, and web browsers to enhance their capabilities; NOT solely depending on the LLMs.
Below, we provide an overview of our XLang Agents framework. Each concept will be elaborated further in subsequent sections.
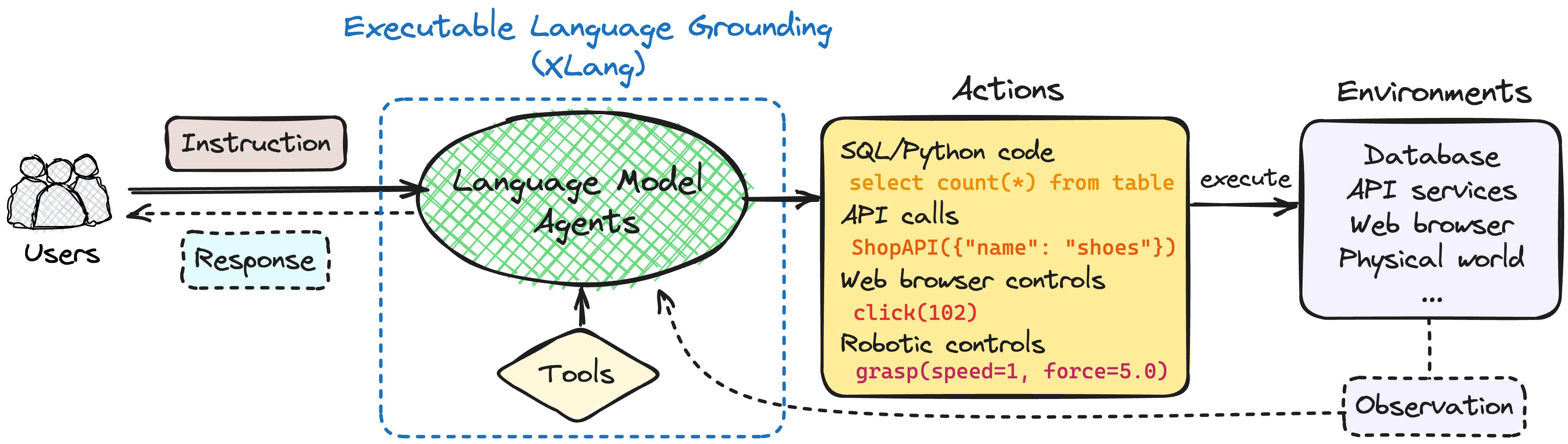
Agent
Agent accepts the user intent(s) as input; then it iteratively generates & executes actions to satisfy the user intent(s). An agent consists of an LLM-based policy to predict the next action, and an Action Space to select from.
In reinforcement learning (RL), an "agent" is a decision-maker interacting with an environment to fulfill a goal. It learns via a feedback loop, adjusting its strategy based on rewards or penalties to maximize total rewards over time.
Recently, in NLP and robotics, "agent" refers to a system or model that interacts with its environment, either directly or with tools. Typically, it's a large language model(LLM) prompted to act or a custom-tailored mid-sized model. It follows language directives and predicts actions by predicting tokens that activate API functions with specific parameters.
LLM-based Policy
Large Language Model(LLM), with modern prompting methods and abundant context length, can serve as a training-free capable policy network that takes the history actions and observations as contexts.
LLMs are Transformer-based models that contain billions or even trillions of parameters, and are trained on a large corpus of text data. Generally, LLMs have strong capabilities in language understanding and generation, especially in following the instruction, planning, and reasoning, thus can be prompted to serve as the policy network of agent to do a series of tasks, proved by many recent works.
Action Space
Action is a general function that can be called(executed). Action space is the collection of available actions to the agent. As LLMs can naturally generate natural language(NL), the action space is composed of:
- action names & arguments
- free-form NL tokens
Environment
Environment is the external system in which actions are executed, and in response, it provides observations as the outcome of those actions back to the agent.
In reinforcement learning (RL), the "environment" refers to the external system with which the agent interacts. It embodies everything outside the agent and provides a context in which the agent operates. The agent doesn't have direct control over the environment but can influence it through actions.
The concepts of environment can be extended to the world of natural language processing (NLP). In this case the environment can be a code interpreter, a set of tools, a web browser, or the entire world.
Tool
A Tool serves as a high-level abstraction of a series of low-level actions within an environment, streamlining multiple steps to achieve a specific goal. Essentially, a tool functions as a component of the environment, offering a shortcut that encapsulates a sequence of actions for easy accessibility. For instance, Serpapi is a tool that simplifies the process of users searching on Google.
In-context Human Feedback
One key feature that sets XLang Agents apart from recent LLM-powered agents is the In-context Human Feedback mechanism. This allows humans to engage in multi-turn chats with the agents, and their feedback is directly integrated into the agent's context to guide subsequent decisions. This offers two notable benefits:
Assisting in Task Completion. It adds a unique dimension: users, who best know the task goal at hand, can provide immediate and pragmatic feedback after evaluating the agent's responses, actions, and observations. This ensures the agent is equipped with additional information or guidance to effectively finish the task.
Promoting Deeper Task Exploration. Often, users' true intentions or further queries emerge as a conversation progresses and deepens. With in-context human feedback, users can spontaneously introduce new or more detailed objectives to the agent as the discourse unfolds.
Take the conversation below as an example:
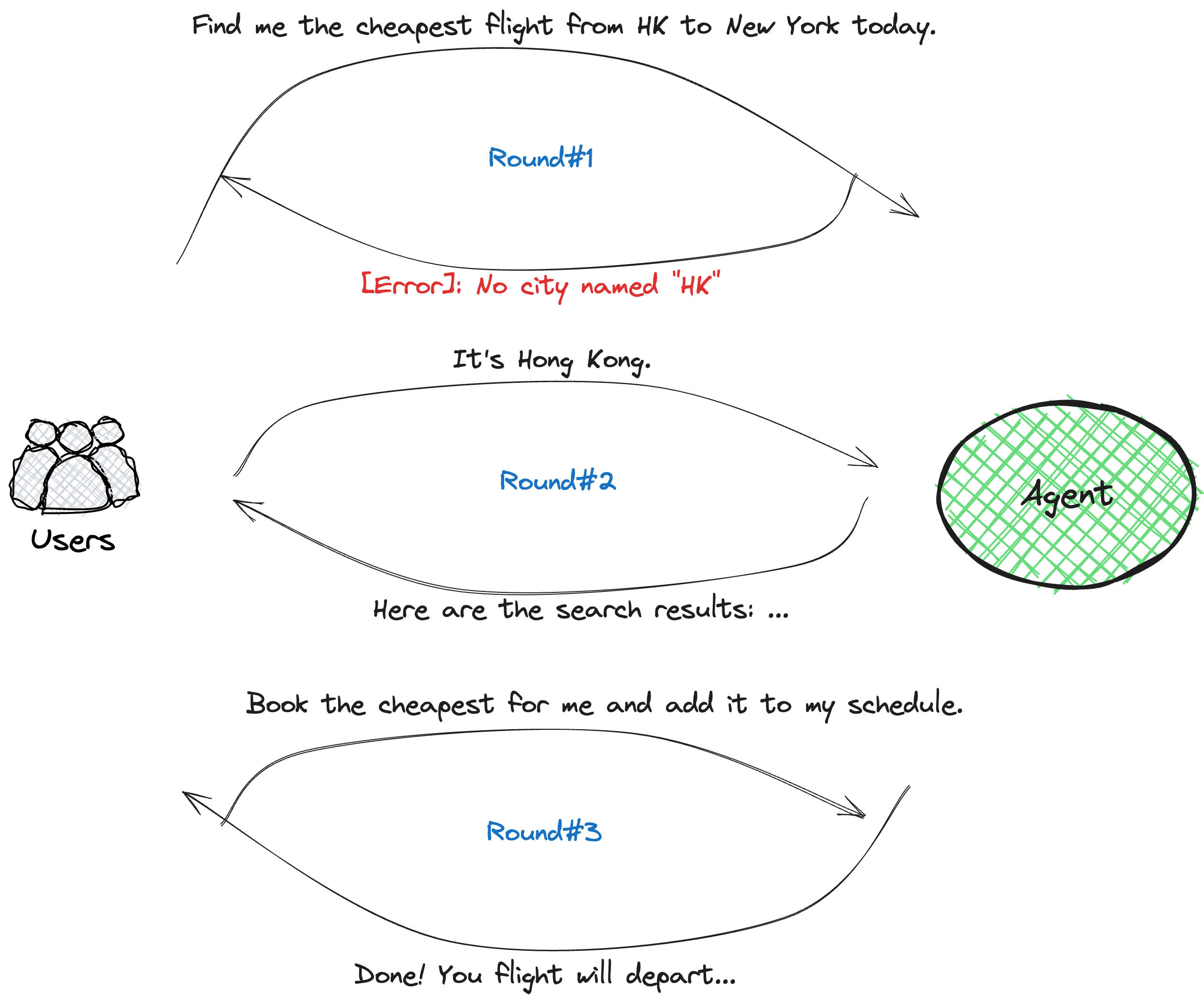
In round #1, users asked the agent to "find the cheapest flight from HK to New York today." However, the agent couldn't recognize the abbreviation "HK" for Hong Kong.
So, in round #2, users clarified by explicitly stating, "It's Hong Kong", enabling the agent to successfully locate the desired flight tickets.
Then, in round #3, after reviewing the listed flights, users expanded their initial request, asking the agent to book the cheapest flight and add it to their schedule.